Parcels structure overview#
The flexibility of Parcels allows for a wide range of applications and to build complex simulations. In order to help structure your code, this tutorial describes the structure that a Parcels script uses.
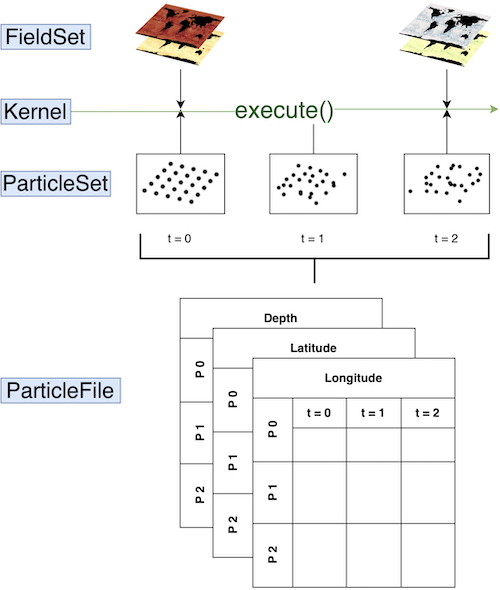
Code that uses Parcels is generally built up from four different components:
FieldSet. Load and set up the fields. These can be velocity fields that are used to advect the particles, but it can also be e.g. temperature.
ParticleSet. Define the type of particles. Also additional
Variablescan be added to the particles (e.g. temperature, to keep track of the temperature that particles experience).Kernels. Define and compile kernels. Kernels perform some specific operation on the particles every time step (e.g. interpolate the temperature from the temperature field to the particle location).
Execution and output. Execute the simulation and write and store the output in a Zarr file.
Optimising and parallelising. Optimise and parallelise the code to run faster.
We discuss each component in more detail below.
1. FieldSet#
Parcels provides a framework to simulate the movement of particles within an existing flow field environment. To start a parcels simulation we must define this environment with the FieldSet class. The minimal requirements for this Fieldset are that it must contain the 'U' and 'V' fields: the 2D hydrodynamic data that will move the particles in a horizontal direction. Additionally, it can contain e.g. a temperature or vertical flow field.
A fieldset can be loaded with FieldSet.from_netcdf, if the model output with the fields is written in NetCDF files. This function requires filenames, variables and dimensions.
In this example, we only load the 'U' and 'V' fields, which represent the zonal and meridional flow velocity. First, fname points to the location of the model output.
[1]:
import parcels
example_dataset_folder = parcels.download_example_dataset("GlobCurrent_example_data")
fname = f"{example_dataset_folder}/*.nc"
filenames = {"U": fname, "V": fname}
Second, we have to specify the 'U' and 'V' variable names, as given by the NetCDF files.
[2]:
variables = {
"U": "eastward_eulerian_current_velocity",
"V": "northward_eulerian_current_velocity",
}
Third, we specify the names of the variable dimensions, as given by the NetCDF files.
[3]:
# In the GlobCurrent data the dimensions are also called 'lon', 'lat' and 'time
dimensions = {
"U": {"lat": "lat", "lon": "lon", "time": "time"},
"V": {"lat": "lat", "lon": "lon", "time": "time"},
}
Finally, we load the fieldset.
[4]:
fieldset = parcels.FieldSet.from_netcdf(filenames, variables, dimensions)
For more advanced tutorials on creating FieldSets:#
If you use interpolated output (such as from the Copernicus Marine Service):#
Or download and use the data on the original C-grid from Mercator Ocean International directly
If you are working with field data on different grids:#
If you want to combine different velocity fields:#
2. ParticleSet#
Once the environment has a FieldSet object, you can start defining your particles in a ParticleSet object. This object requires:
The
FieldSetobject in which the particles will be released.The type of
Particle: Either aJITParticleorScipyParticle.Initial conditions for each
Variabledefined in theParticle, most notably the release locations inlonandlat.
[5]:
# Define a new particleclass with Variable 'age' with initial value 0.
AgeParticle = parcels.JITParticle.add_variable(parcels.Variable("age", initial=0))
pset = parcels.ParticleSet(
fieldset=fieldset, # the fields that the particleset uses
pclass=AgeParticle, # define the type of particle
lon=29, # release longitude
lat=-33, # release latitude
)
For more advanced tutorials on how to setup your ParticleSet:#
For more information on how to implement Particle types with specific behaviour, see the section on writing your own kernels.
3. Kernels#
Kernels are little snippets of code, which are applied to every particle in the ParticleSet, for every time step during a simulation. Basic kernels are included in Parcels, among which several types of advection kernels. AdvectionRK4 is the main advection kernel for two-dimensional advection, which is also used in this example.
One can also write custom kernels, to add certain types of ‘behaviour’ to the particles. Kernels can then be combined with the + operator (where at least one of the kernels needs to be cast to a pset.Kernel() object), or by creating a list of the kernels. Note that the kernels are executed in order.
[6]:
# Create a custom kernel which displaces each particle southward
def NorthVel(particle, fieldset, time):
if time > 10 * 86400 and time < 10.2 * 86400:
vvel = -1e-4
particle_dlat += vvel * particle.dt
# Create a custom kernel which keeps track of the particle age (minutes)
def Age(particle, fieldset, time):
particle.age += particle.dt / 3600
# define all kernels to be executed on particles using an (ordered) list
kernels = [Age, NorthVel, parcels.AdvectionRK4]
Some key limitations exist to the Kernels that everyone who wants to write their own should be aware of:
Every Kernel must be a function with the following (and only those) arguments:
(particle, fieldset, time)In order to run successfully in JIT mode, Kernel definitions can only contain the following types of commands:
Basic arithmetical operators (
+,-,*,/,**) and assignments (=).Basic logical operators (
<,==,!=,>,&,|). Note that you can use a statement likeparticle.lon != particle.lonto check ifparticle.lonis NaN (sincemath.nan != math.nan).ifandwhileloops, as well asbreakstatements. Note thatfor-loops are not supported in JIT mode.Interpolation of a
Fieldfrom theFieldSetat a[time, depth, lat, lon]point, using square brackets notation. For example, to interpolate the zonal velocity (U) field at the particle location, use the following statement:value = fieldset.U[time, particle.depth, particle.lat, particle.lon]
or simply
value = fieldset.U[particle]
Functions from the maths standard library.
Functions from the custom
ParcelsRandomlibrary at theparcels.rngmodule. Note that these have to be used asParcelsRandom.random(),ParcelsRandom.uniform()etc for the code to compile.Simple
printstatements, such as:print("Some print")print(particle.lon)print(f"particle id: {particle.id}")print(f"lon: {particle.lon}, lat: {particle.lat}")
Local variables can be used in Kernels, and these variables will be accessible in all concatenated Kernels. Note that these local variables are not shared between particles, and also not between time steps.
It is advised not to update the particle location (
particle.lon,particle.lat,particle.depth, and/orparticle.time) directly, as that can negatively interfere with the way that particle movements by different kernels are vectorially added. Useparticle_dlon,particle_dlat,particle_ddepth, and/orparticle_dtimeinstead. See also the kernel loop tutorial.Note that one has to be careful with writing kernels for vector fields on Curvilinear grids. While Parcels automatically rotates the U and V field when necessary, this is not the case for for example wind data. In that case, a custom rotation function will have to be written.
A note on Field interpolation notation
Note that for the interpolation of a
Field, the second option (value = fieldset.U[particle]) is not only a short-hand notation for the (value = fieldset.U[time, particle.depth, particle.lat, particle.lon]); it is actually a faster way to interpolate the field at the particle location in Scipy mode, as described in this section of the JIT-vs-Scipy tutorial.
For more advanced tutorials on writing custom kernels that work on custom particles:#
4. Execution and output#
The final part executes the simulation, given the ParticleSet, FieldSet and Kernels, that have been defined in the previous steps. If you like to store the particle data generated in the simulation, you define the ParticleFile to which the output of the kernel execution as well as - optionally - any user-specified metadata (see the Working with Parcels output tutorial for more info) will be written. Then,
on the ParticleSet you have defined, you can use the method ParticleSet.execute() which requires the following arguments:
The kernels to be executed.
The
runtimedefining how long the execution loop runs. Alternatively, you may define theendtimeat which the execution loop stops.The timestep
dtat which to execute the kernels.(Optional) The
ParticleFileobject to write the output to.
[7]:
output_file = pset.ParticleFile(
name="GCParticles.zarr", # the name of the output file
outputdt=3600, # the time period between consecutive out output steps
chunks=(1, 10), # the chunking of the output file (number of particles, timesteps)
)
pset.execute(
kernels, # the kernel (which defines how particles move)
runtime=86400 * 24, # the total length of the run in seconds
dt=300, # the timestep of the kernel in seconds
output_file=output_file,
)
INFO: Output files are stored in GCParticles.zarr.
100%|██████████| 2073600.0/2073600.0 [00:04<00:00, 444884.89it/s]
A note on output chunking
Note the use of the chunks argument in the pset.ParticleFile() above. This controls the ‘chunking’ of the output file, which is a way to optimize the writing of the output file. The default chunking for the output in Parcels is (number of particles in initial particleset, 1). Note that this default may not be very efficient if you use repeatdt to release a relatively small number of particles many times during the simulation and/or you expect to output a lot of timesteps
(e.g. more than 1000).
In the first case, it is best to increase the first argument of chunks to 10 to 100 times the size of your initial particleset. In the second case, it is best to increase the second argument of chunks to 10 to 1000, depending a bit on the size of your initial particleset.
In either case, it will generally be much more efficient if chunks[0]*chunks[1] is (much) greater than several thousand.
See also the advanced output in zarr format tutorial for more information on this. The details will depend on the nature of the filesystem the data is being written to, so it is worth to optimise this parameter in your runs, as it can significantly speed up the writing of the output file and thus the runtime of pset.execution().
After running your simulation, you probably want to analyze the output. You can use the trajan package for some simple plotting. However, we recommend you write your own code to analyze your specific output and you can probably separate the analysis from the simulation.
For more tutorials on the parcels output:#
5. Optimising and parallelising#
On linux and macOS, Parcels can be run in parallel using MPI. This can be done by running the script with
mpirun -np <number of processors> python <scriptname>.py
The script will then run in parallel on the number of cores specified. Note that this is a fairly ‘simple’ implementation of paralelisation, where the number of particles is simply spread over the cores (using a kdtree for some optimisation). This means that the more cores you use, the less particles each core will have to handle, and the faster the simulation will run. However, the speedup is not linear, as each core will need to load its own FieldSet.
For more tutorials on MPI and parallelisation:#
Another good way to optimise Parcels and speed-up execution is to chunk the FieldSet with dask, using the chunksize argument in the FieldSet creation. This will allow Parcels to load the FieldSet in chunks.
Using chunking can be especially useful when working with large datasets and when the particles only occupy a small region of the domain.
Note that the default is chunksize=None, which means that the FieldSet is loaded in its entirety. This is generally the most efficient way to load the FieldSet when the particles are spread out over the entire domain.